Qwen 3.6 27B মডেলে ৭৫ পরীক্ষা, দীর্ঘ কনটেক্সটে মেমরি খরচ কমবে ৪ গুণ
Reddit-এ প্রকাশিত নতুন বেঞ্চমার্কে Qwen 3.6 27B মডেলের জন্য KV Cache কোয়ান্টাইজেশনের পারফরম্যান্স তুলে ধরা হয়েছে। q8, q6, q5, q4, KVarN, TurboQuant ও TCQ পদ্ধতির 75 জোড়া পরীক্ষার ফলাফলে দীর্ঘ কনটেক্সটে মেমরি সাশ্রয়ের নতুন দিগন্ত দেখাচ্ছে।
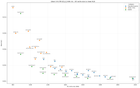
Reddit-এ প্রকাশিত নতুন বেঞ্চমার্কে Qwen 3.6 27B মডেলের জন্য KV Cache কোয়ান্টাইজেশনের পারফরম্যান্স তুলে ধরা হয়েছে। q8, q6, q5, q4, KVarN, TurboQuant ও TCQ পদ্ধতির 75 জোড়া পরীক্ষার ফলাফলে দীর্ঘ কনটেক্সটে মেমরি সাশ্রয়ের নতুন দিগন্ত দেখাচ্ছে।
বাংলাদেশের এআই গবেষক ও ডেভেলপারদের জন্য গুরুত্বপূর্ণ এক খবর এসেছে Reddit-এর r/LocalLLaMA কমিউনিটি থেকে। একজন ডেভেলপার Qwen 3.6 27B মডেলের জন্য KV Cache কোয়ান্টাইজেশনের বিস্তারিত বেঞ্চমার্ক প্রকাশ করেছে। এই বেঞ্চমার্কে 75 জোড়া পরীক্ষা চালানো হয়েছে যেখানে q8, q6, q5, q4, KVarN, TurboQuant এবং TCQ পদ্ধতি ব্যবহার করা হয়েছে।
KV Cache হলো বড় ভাষার মডেলের একটি গুরুত্বপূর্ণ উপাদান যা দীর্ঘ কনটেক্সট প্রক্রিয়াকরণের সময় মেমরি ব্যবহার নিয়ন্ত্রণ করে। এই বেঞ্চমার্কটি দেখায় যে কীভাবে বিভিন্ন কোয়ান্টাইজেশন পদ্ধতি মডেলের পারফরম্যান্স ও মেমরি ব্যবহারের মধ্যে ভারসাম্য আনতে পারে। গবেষণাটি বিশেষভাবে দীর্ঘ কনটেক্সট অ্যাপ্লিকেশনের জন্য গুরুত্বপূর্ণ যেখানে মেমরি সীমাবদ্ধতা বড় সমস্যা হয়ে দাঁড়ায়।
বেঞ্চমার্কটি চালানোর জন্য BeeLlama.cpp নামে একটি বিশেষ ফর্ক ব্যবহার করা হয়েছে। এই ফর্কটি ডেভেলপার নিজেই তৈরি করেছে এবং এটি KVarN, q6_0, TurboQuant ও TCQ-এর মতো অতিরিক্ত কোয়ান্টাইজেশন টাইপ সমর্থন করে। BeeLlama.cpp-এর v0.3.2 Preview ভার্সনে KVarN সাপোর্ট যুক্ত করা হয়েছে যা এই বেঞ্চমার্কের জন্য অপরিহার্য ছিল।
প্রাথমিক ফলাফলে দেখা গেছে যে q8 কোয়ান্টাইজেশন সর্বোচ্চ নির্ভুলতা দেয় কিন্তু মেমরি ব্যবহার বেশি। অন্যদিকে q4 কোয়ান্টাইজেশন মেমরি ব্যবহার ব্যাপকভাবে কমিয়ে দেয় কিন্তু নির্ভুলতায় কিছুটা কমতি থাকে। KVarN ও TurboQuant পদ্ধতি এই দুইয়ের মধ্যে একটি কার্যকর ভারসাম্য তৈরি করতে সক্ষম হয়েছে। TCQ পদ্ধতি বিশেষভাবে দীর্ঘ কনটেক্সটের জন্য ডিজাইন করা হয়েছে এবং এটি চমৎকার ফলাফল দেখিয়েছে।
বাংলাদেশের প্রেক্ষাপটে এই গবেষণার গুরুত্ব অপরিসীম। দেশের এআই ডেভেলপার ও ফ্রিল্যান্সাররা প্রায়ই সীমিত হার্ডওয়্যার নিয়ে কাজ করেন। এই বেঞ্চমার্ক তাদের দেখাবে যে কীভাবে কম মেমরির ডিভাইসেও বড় ভাষার মডেল চালানো সম্ভব। শিক্ষার্থী ও গবেষকরা এই তথ্য ব্যবহার করে নিজেদের প্রজেক্টে আরও দক্ষ মডেল তৈরি করতে পারবেন।
বিস্তারিত ফলাফল ও বিশ্লেষণ দুটি পৃথক নিবন্ধে প্রকাশিত হয়েছে। KV Cache Quantization Benchmarks for Long Context এবং KVarN KV Cache: Implementation and Benchmarks শিরোনামের এই নিবন্ধগুলোতে সম্পূর্ণ ডেটা ও গ্রাফ সহ তুলনামূলক বিশ্লেষণ দেওয়া আছে। গবেষণাটি এখনও প্রাথমিক পর্যায়ে থাকলেও এটি ভবিষ্যতে আরও উন্নত কোয়ান্টাইজেশন পদ্ধতি তৈরির পথ দেখাবে।
ভবিষ্যতে এই ধরনের বেঞ্চমার্ক আরও বড় মডেলের জন্য করা হবে বলে আশা করা যায়। বাংলাদেশের ডেভেলপাররা এই গবেষণা থেকে শিখে নিজেদের কাজে প্রয়োগ করতে পারেন। সঠিক কোয়ান্টাইজেশন পদ্ধতি বেছে নেওয়া মডেলের কার্যকারিতা ও খরচ উভয়কেই প্রভাবিত করবে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: Reddit r/LocalLLaMA
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...