বাংলাদেশে AI মডেল চালাতে চান? Qwen3.6-27B-এর সেরা ভার্সন কোনটি
Reddit-এর r/LocalLLaMA কমিউনিটিতে প্রকাশিত এক বেঞ্চমার্কে Qwen3.6-27B মডেলের বিভিন্ন কোয়ান্টাইজড ভার্সনের তুলনা করা হয়েছে। Unsloth, mradermacher, cHunter789 ও Ununnilium-এর তৈরি মডেলগুলোর মধ্যে কোনটি বেস BF16 ভার্সনের সবচেয়ে কাছাকাছি, তা জানতে পড়ুন।
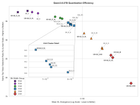
Reddit-এর r/LocalLLaMA কমিউনিটিতে প্রকাশিত এক বেঞ্চমার্কে Qwen3.6-27B মডেলের বিভিন্ন কোয়ান্টাইজড ভার্সনের তুলনা করা হয়েছে। Unsloth, mradermacher, cHunter789 ও Ununnilium-এর তৈরি মডেলগুলোর মধ্যে কোনটি বেস BF16 ভার্সনের সবচেয়ে কাছাকাছি, তা জানতে পড়ুন।
বড় ভাষার মডেলকে ছোট ও দ্রুত করার জন্য কোয়ান্টাইজেশন একটি গুরুত্বপূর্ণ পদ্ধতি। সম্প্রতি Reddit-এর r/LocalLLaMA কমিউনিটিতে Qwen3.6-27B মডেলের বিভিন্ন কোয়ান্টাইজড ভার্সনের একটি বিস্তারিত বেঞ্চমার্ক প্রকাশিত হয়েছে। এই বেঞ্চমার্কে Q8 থেকে শুরু করে Q2 পর্যন্ত মোট আটটি ভিন্ন ভিন্ন কোয়ান্টাইজেশন লেভেলের পারফরম্যান্স তুলনা করা হয়েছে।
বেঞ্চমার্কটিতে চারটি জনপ্রিয় কোয়ান্টাইজড মডেলের সেট পরীক্ষা করা হয়েছে। এগুলো তৈরি করেছে unsloth, mradermacher, cHunter789 এবং Ununnilium নামক প্রতিষ্ঠান ও ডেভেলপাররা। প্রতিটি সেটের মধ্যে Q8, Q6, Q5, Q4, Q3 এবং Q2 লেভেলের মডেল অন্তর্ভুক্ত ছিল। মূল মডেল হিসেবে ব্যবহার করা হয়েছে BF16 (Brain Floating Point 16) ভার্সন, যা সবচেয়ে নির্ভুল কিন্তু সবচেয়ে বড়।
পরীক্ষার জন্য llama.cpp-এর llama-perplexity টুল ব্যবহার করা হয়েছে। এটি একটি স্ট্যান্ডার্ড বেঞ্চমার্কিং টুল যা কোয়ান্টাইজড মডেলের আউটপুটের গুণমান মূল মডেলের সাথে তুলনা করে। দুটি প্রধান মেট্রিক ব্যবহার করা হয়েছে। প্রথমটি হলো Mean KLD (Kullback-Leibler Divergence), যা দুটি মডেলের প্রেডিকশনের মধ্যে পার্থক্য মাপে। দ্বিতীয়টি হলো Same Top P Percentage, যা দেখে কোয়ান্টাইজড মডেল কতবার মূল মডেলের মতো একই শীর্ষ প্রেডিকশন তৈরি করেছে।
সব পরীক্ষা একই কন্টেক্সট লেংথে (8192 টোকেন) এবং একই KV ক্যাশে কোয়ান্টাইজেশন (q8_0) ব্যবহার করে পরিচালিত হয়েছে। এর ফলে ফলাফলগুলো তুলনাযোগ্য এবং নির্ভরযোগ্য হয়েছে। প্রাথমিক ফলাফল অনুযায়ী, উচ্চতর বিট রেটের কোয়ান্টাইজেশন (Q8, Q6) স্বাভাবিকভাবেই মূল মডেলের সবচেয়ে কাছাকাছি পারফর্ম করেছে। তবে Q4 এবং Q3 লেভেলেও মানসম্মত পারফরম্যান্স দেখা গেছে, যা স্থানীয় ডিভাইসে বড় মডেল চালানোর জন্য গুরুত্বপূর্ণ।
বাংলাদেশের প্রেক্ষাপটে এই বেঞ্চমার্কটি বিশেষভাবে তাৎপর্যপূর্ণ। বাংলাদেশের অনেক ডেভেলপার, ফ্রিল্যান্সার এবং গবেষকের কাছে উচ্চক্ষমতাসম্পন্ন GPU বা ক্লাউড সার্ভিসে প্রবেশাধিকার সীমিত। কোয়ান্টাইজড মডেল ব্যবহার করে তারা নিজেদের কম্পিউটারে বা ল্যাপটপে বড় ভাষার মডেল চালাতে পারেন। এই বেঞ্চমার্কটি তাদের সঠিক মডেল নির্বাচনে সহায়তা করবে।
এই বেঞ্চমার্কটি দেখায় যে, কোয়ান্টাইজেশন প্রযুক্তি দিন দিন আরও পরিণত হচ্ছে। Qwen3.6-27B-এর মতো শক্তিশালী মডেলকে Q4 বা Q3 লেভেলে কোয়ান্টাইজ করেও সন্তোষজনক ফলাফল পাওয়া সম্ভব। ভবিষ্যতে আরও উন্নত কোয়ান্টাইজেশন পদ্ধতি আসবে যা মডেলের গুণমান আরও কম ক্ষতি করবে বলে আশা করা যায়।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: Reddit r/LocalLLaMA
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...