RAG সিস্টেমের আসল শত্রু চিহ্নিত: ভুল ডকুমেন্ট বিভাজন, সমাধান জানুন
ডেভেলপাররা প্রায়ই RAG সিস্টেমের ত্রুটি খুঁজতে গিয়ে embeddings বা vector database-কে দায়ী করেন। কিন্তু dev.to ML-এর এক বিশ্লেষণে দেখা গেছে, আসল সমস্যা লুকিয়ে আছে ডকুমেন্ট বিভাজন বা chunking-এ। এই নিবন্ধে জানুন কেন chunking-কে গুরুত্ব দেওয়া জরুরি এবং কীভাবে এটি ঠিক করবেন।
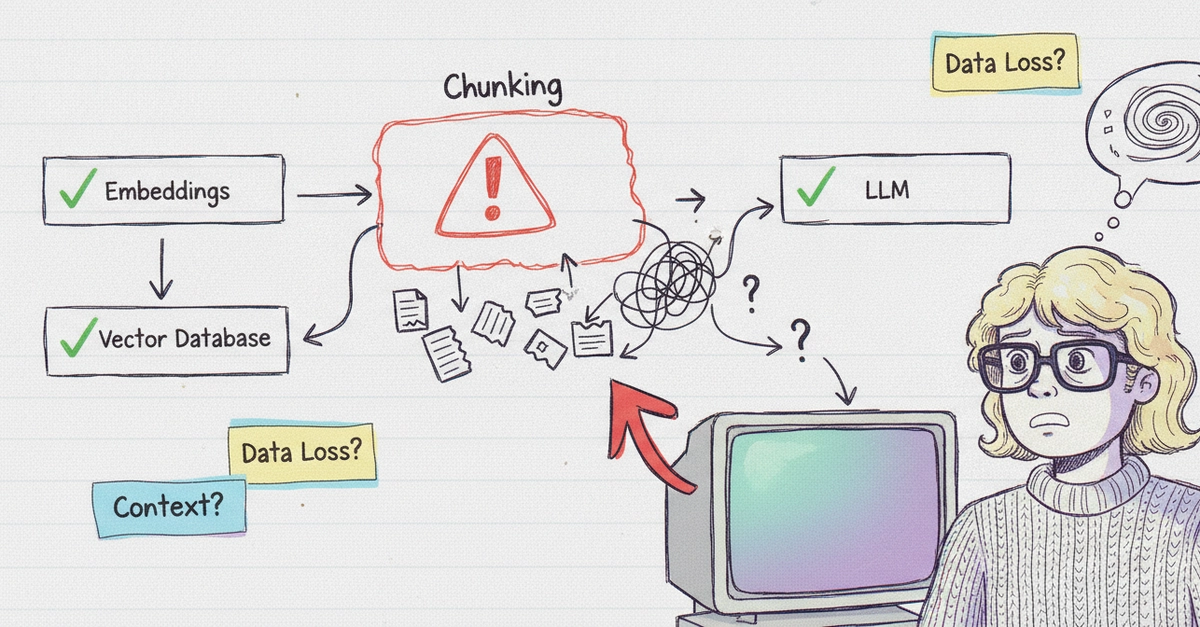
ডেভেলপাররা প্রায়ই RAG সিস্টেমের ত্রুটি খুঁজতে গিয়ে embeddings বা vector database-কে দায়ী করেন। কিন্তু dev.to ML-এর এক বিশ্লেষণে দেখা গেছে, আসল সমস্যা লুকিয়ে আছে ডকুমেন্ট বিভাজন বা chunking-এ। এই নিবন্ধে জানুন কেন chunking-কে গুরুত্ব দেওয়া জরুরি এবং কীভাবে এটি ঠিক করবেন।
RAG বা Retrieval-Augmented Generation সিস্টেম নিয়ে কাজ করা ডেভেলপাররা প্রায়ই একটি সাধারণ সমস্যার মুখোমুখি হন। ভালো embeddings, সঠিক vector database এবং শক্তিশালী LLM ব্যবহার করেও উত্তর প্রায়ই অসম্পূর্ণ বা অপ্রাসঙ্গিক হয়। সম্প্রতি dev.to ML-এ প্রকাশিত একটি নিবন্ধে এই সমস্যার প্রকৃত কারণ চিহ্নিত করা হয়েছে। সেটি হলো ডকুমেন্ট বিভাজন বা chunking কৌশল।
বেশিরভাগ ডেভেলপার RAG শেখার সময় ধরে নেন যে সবচেয়ে কঠিন অংশ হলো embeddings, vector databases এবং LLMs। কিন্তু বাস্তবে দেখা গেছে, এই উপাদানগুলো সঠিকভাবে কাজ করলেও ফলাফল হতাশাজনক হতে পারে। কারণটি হলো ডকুমেন্টগুলোকে সঠিকভাবে ভাগ না করা। যখন একটি ডকুমেন্টকে ছোট ছোট অংশে বিভক্ত করা হয়, তখন প্রতিটি অংশের অর্থ এবং প্রসঙ্গ হারিয়ে যেতে পারে। ফলে LLM সঠিক তথ্য খুঁজে পায় না এবং অসম্পূর্ণ উত্তর দেয়।
Chunking একটি অত্যন্ত গুরুত্বপূর্ণ কিন্তু প্রায়ই উপেক্ষিত উপাদান। এটি নির্ধারণ করে কিভাবে একটি বড় ডকুমেন্টকে ছোট ছোট টুকরোতে ভাগ করা হবে। প্রতিটি টুকরো বা chunk পরে vector database-এ সংরক্ষিত হয়। যখন কোনো প্রশ্ন আসে, সিস্টেম সবচেয়ে প্রাসঙ্গিক chunk খুঁজে বের করে এবং সেটি LLM-কে পাঠায়। যদি chunk গুলো খুব ছোট হয়, তাহলে প্রসঙ্গ হারিয়ে যায়। যদি খুব বড় হয়, তাহলে অনেক অপ্রাসঙ্গিক তথ্য চলে আসে। উভয় ক্ষেত্রেই উত্তর মানসম্মত হয় না।
ডিবাগিং শুরু করার সময় প্রথমেই document splitting কৌশল পরীক্ষা করা উচিত। dev.to ML-এর নিবন্ধে বলা হয়েছে, chunk size, overlap এবং splitting strategy এই তিনটি বিষয় ঠিক করা জরুরি। একটি সাধারণ নিয়ম হলো প্রতিটি chunk-এ একটি সম্পূর্ণ ধারণা বা প্যারাগ্রাফ রাখা। প্রয়োজনে overlap ব্যবহার করা যেতে পারে যাতে প্রসঙ্গ ধরে রাখা যায়। উদাহরণস্বরূপ, 500 টোকেনের chunk এবং 50 টোকেনের overlap একটি ভালো শুরু হতে পারে। তবে এটি নির্ভর করে ডকুমেন্টের ধরন এবং ভাষার ওপর।
বাংলাদেশের ডেভেলপার এবং ফ্রিল্যান্সারদের জন্য এই তথ্য বিশেষভাবে গুরুত্বপূর্ণ। দেশে AI এবং মেশিন লার্নিং নিয়ে কাজ করা অনেক তরুণ গবেষক আছেন যারা RAG-ভিত্তিক অ্যাপ্লিকেশন তৈরি করছেন। তারা যদি chunking-কে গুরুত্ব না দেন, তাহলে তাদের সিস্টেমের কর্মক্ষমতা হ্রাস পাবে। অন্যদিকে, সঠিক chunking কৌশল ব্যবহার করলে তারা আরও নির্ভরযোগ্য এবং প্রাসঙ্গিক উত্তর দিতে পারবেন। এটি বিশেষ করে চ্যাটবট, ডকুমেন্ট সার্চ ইঞ্জিন এবং প্রশ্নোত্তর সিস্টেমের জন্য কার্যকর।
সঠিক chunking কৌশল বেছে নেওয়ার জন্য কিছু পরীক্ষা-নিরীক্ষা করা প্রয়োজন। প্রথমে ছোট chunk দিয়ে শুরু করুন এবং ধীরে ধীরে বড় করুন। প্রতিটি পরিবর্তনের পর ফলাফল মূল্যায়ন করুন। মনে রাখবেন, কোনো একক পদ্ধতি সবার জন্য কাজ করে না। আপনার ডেটা এবং ব্যবহারের ক্ষেত্র অনুযায়ী সেরা সমাধান বেছে নিন। RAG সিস্টেমের ভবিষ্যত নির্ভর করে এই ছোট কিন্তু গুরুত্বপূর্ণ উপাদানটির সঠিক বাস্তবায়নের ওপর।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: dev.to ML
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...