Mistral OCR 4 লঞ্চ: ডকুমেন্ট থেকে ডেটা বের করে ৩ গুণ দ্রুত কাজ করুন
Mistral AI তাদের OCR 4 মডেল লঞ্চ করেছে যা ডকুমেন্ট থেকে স্ট্রাকচার্ড ডেটা বের করে। এটি বাউন্ডিং বক্স, টাইপড ক্লাসিফিকেশন এবং কনফিডেন্স স্কোর দেয়। মডেলটি 170 ভাষা সমর্থন করে এবং একটি সেল্ফ-হোস্টেড কন্টেইনারে চলে।
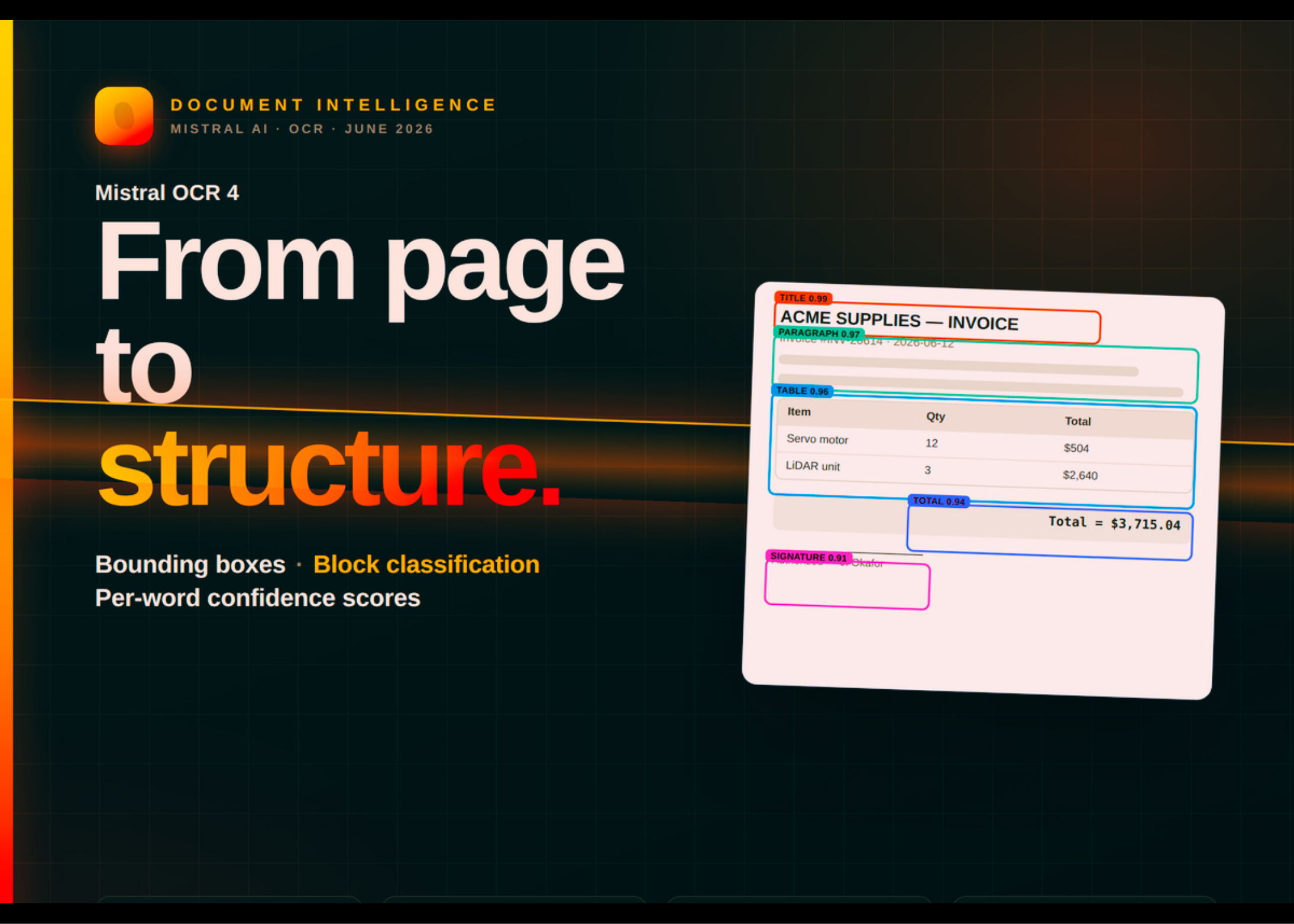
Mistral AI তাদের OCR 4 মডেল লঞ্চ করেছে যা ডকুমেন্ট থেকে স্ট্রাকচার্ড ডেটা বের করে। এটি বাউন্ডিং বক্স, টাইপড ক্লাসিফিকেশন এবং কনফিডেন্স স্কোর দেয়। মডেলটি 170 ভাষা সমর্থন করে এবং একটি সেল্ফ-হোস্টেড কন্টেইনারে চলে।
Mistral AI তাদের নতুন OCR 4 মডেল লঞ্চ করেছে। এটি 23 জুন 2026 তারিখে প্রকাশিত হয়েছে। এই মডেলটি আগের সংস্করণগুলোর তুলনায় একটি বড় পরিবর্তন এনেছে। এটি আর শুধু টেক্সট এক্সট্রাক্ট করে না বরং স্ট্রাকচার্ড আউটপুট দেয়।
OCR 4 প্রতিটি ব্লকের জন্য বাউন্ডিং বক্স, টাইপড ক্লাসিফিকেশন এবং কনফিডেন্স স্কোর রিটার্ন করে। পৃষ্ঠা ও শব্দ পর্যায়েও কনফিডেন্স স্কোর পাওয়া যায়। এটি ডকুমেন্ট প্রসেসিংকে আরও নির্ভরযোগ্য করে তোলে।
এই মডেলটি 170 টি ভাষা সমর্থন করে। এটি একটি একক সেল্ফ-হোস্টেড কন্টেইনারে চলে। ফলে ব্যবহারকারীরা নিজেদের সার্ভারে এটি স্থাপন করতে পারেন। এটি ডেটা প্রাইভেসি নিশ্চিত করে।
OCR 4 বিশেষভাবে RAG, এজেন্টিক এবং এন্টারপ্রাইজ সার্চ পাইপলাইনের জন্য ডিজাইন করা হয়েছে। একটি মাত্র API এন্ডপয়েন্টের মাধ্যমে সাইটেশন-রেডি ইনপুট সরবরাহ করে। এটি বড় ভাষার মডেলগুলোর জন্য নির্ভরযোগ্য তথ্য উৎস তৈরি করে।
বাংলাদেশের ডেভেলপার এবং ফ্রিল্যান্সারদের জন্য এটি গুরুত্বপূর্ণ। তারা এখন স্থানীয় ভাষার ডকুমেন্ট প্রসেসিং করতে পারবেন। ব্যাংক, বীমা এবং সরকারি প্রতিষ্ঠানগুলো কাগজপত্র ডিজিটালাইজ করতে এটি ব্যবহার করতে পারে। শিক্ষার্থীরাও গবেষণাপত্র থেকে তথ্য সংগ্রহ করতে পারবে।
Mistral OCR 4 ডকুমেন্ট প্রসেসিংয়ের একটি নতুন মান তৈরি করেছে। ভবিষ্যতে আরও উন্নত ফিচার আসবে বলে আশা করা যায়। ব্যবহারকারীরা এখন থেকেই তাদের পাইপলাইনে এটি যুক্ত করতে পারেন।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: MarkTechPost
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...