লোকাল AI মডেলের খরচে বড় চমক, Gemma4 জিতল, Qwen3 ব্যর্থ
একটি নতুন গবেষণায় দেখা গেছে, GPU শক্তি পরিমাপ করে লোকাল AI মডেলের প্রতি ১০০০ সঠিক উত্তরের খরচ হিসাব করলে Gemma4:26b সবচেয়ে সস্তা ও নির্ভুল। অন্যদিকে, Qwen3:8b-fp16 সবচেয়ে বেশি খরচ করেও কম নির্ভুলতা দেখিয়েছে।
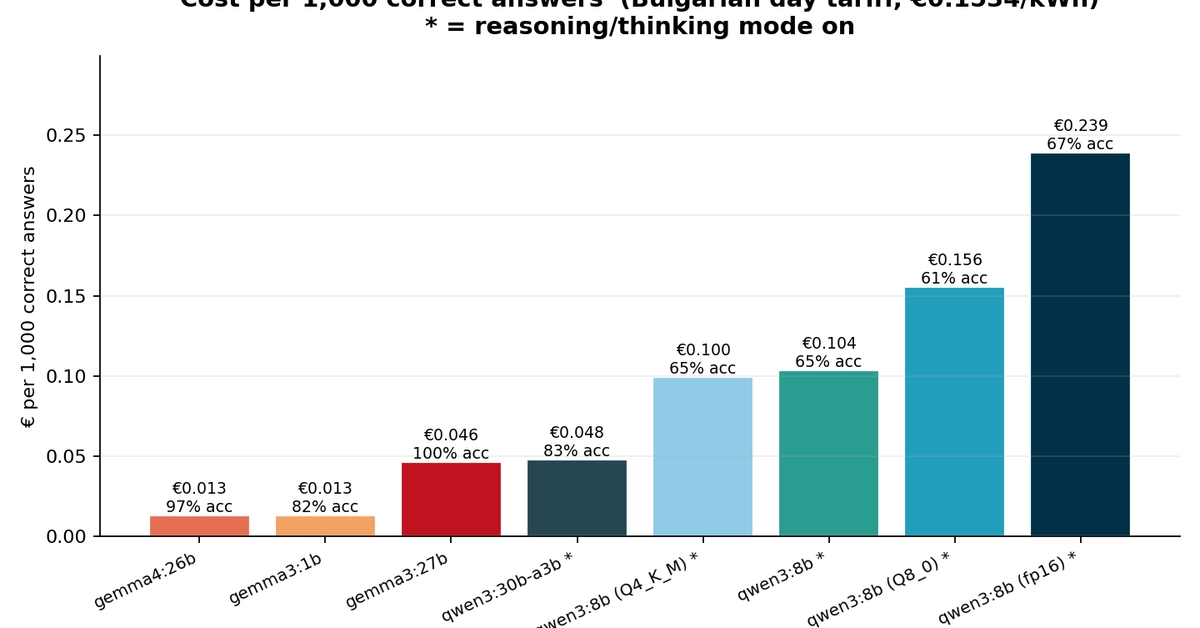
একটি নতুন গবেষণায় দেখা গেছে, GPU শক্তি পরিমাপ করে লোকাল AI মডেলের প্রতি ১০০০ সঠিক উত্তরের খরচ হিসাব করলে Gemma4:26b সবচেয়ে সস্তা ও নির্ভুল। অন্যদিকে, Qwen3:8b-fp16 সবচেয়ে বেশি খরচ করেও কম নির্ভুলতা দেখিয়েছে।
লোকাল লার্জ ল্যাঙ্গুয়েজ মডেল (LLM) ব্যবহারের খরচ নিয়ে একটি নতুন গবেষণায় চমকপ্রদ তথ্য উঠে এসেছে। গবেষকরা 8টি ওপেন-সোর্স Ollama মডেলের GPU শক্তি খরচ মেপে দেখেছেন যে প্রতি ১০০০ সঠিক উত্তরের জন্য কোন মডেলটি সবচেয়ে সাশ্রয়ী। ফলাফলে দেখা গেছে, Google-এর Gemma4:26b মডেলটি 96.9% নির্ভুলতা অর্জন করে মাত্র 0.013 ইউরো খরচ করেছে। অন্যদিকে, Alibaba-এর Qwen3:8b-fp16 মডেলটি সবচেয়ে বেশি ব্যর্থ হয়েছে। এটি 0.239 ইউরো খরচ করে মাত্র 66.7% নির্ভুলতা দেখিয়েছে।
এই গবেষণাটি বিশেষভাবে গুরুত্বপূর্ণ কারণ এটি দেখিয়েছে যে শুধু মডেলের আকার বা নির্ভুলতা নয়, বরং শক্তি খরচের দিক থেকেও মডেল নির্বাচন করা জরুরি। গবেষকরা রিয়েল-টাইম GPU শক্তি মিটারিংয়ের মাধ্যমে হিসাব করেছেন। তারা ওপেন-সোর্স HomeLab Monitor টুল ব্যবহার করে প্রতিটি মডেলের kWh খরচ রেকর্ড করেছেন।
গবেষণায় আরও দেখা গেছে যে reasoning tokens এবং ফুল প্রিসিশন (FP16) ব্যবহার করলে খরচ উল্লেখযোগ্যভাবে বেড়ে যায়, কিন্তু নির্ভুলতা ততটা বাড়ে না। উদাহরণস্বরূপ, Qwen3:8b-fp16 মডেলটি ফুল প্রিসিশনে চলার কারণে সবচেয়ে বেশি বিদ্যুৎ খরচ করেছে, অথচ এর পারফরম্যান্স সবচেয়ে খারাপ ছিল। গবেষকরা বলছেন, অনেক ক্ষেত্রে লোয়ার প্রিসিশন মডেলই যথেষ্ট ভালো কাজ করে।
তবে সবচেয়ে সস্তা মডেল হওয়া সত্ত্বেও Gemma4:26b-এর নির্ভুলতা 96.9% — যা অন্যান্য অনেক ব্যয়বহুল মডেলের চেয়েও ভালো। এটি প্রমাণ করে যে লোকাল AI মডেল নির্বাচনের সময় শুধু দাম বা আকার নয়, বরং নির্ভুলতা ও শক্তি দক্ষতা একসঙ্গে বিবেচনা করা উচিত।
বাংলাদেশের প্রেক্ষাপটে এই গবেষণাটি অত্যন্ত প্রাসঙ্গিক। দেশের ফ্রিল্যান্সার, স্টার্টআপ এবং ছোট ব্যবসাগুলো প্রায়শই ক্লাউড API-এর উচ্চ খরচ এড়াতে লোকাল মডেল ব্যবহার করে। কিন্তু বিদ্যুৎ খরচ ও GPU ব্যবহারের সঠিক হিসাব না থাকায় তারা অনেক সময় অপ্রয়োজনীয় ব্যয় করে ফেলে। এই গবেষণা দেখায় যে সঠিক মডেল নির্বাচন করলে মাসিক বিদ্যুৎ বিল উল্লেখযোগ্যভাবে কমানো সম্ভব।
গবেষণার উপসংহারে বলা হয়েছে, ভবিষ্যতে আরও বেশি মডেল এবং বিভিন্ন GPU কনফিগারেশন নিয়ে পরীক্ষা চালানো হবে। তবে আপাতত Gemma4:26b লোকাল AI ব্যবহারকারীদের জন্য সবচেয়ে সাশ্রয়ী ও নির্ভরযোগ্য পছন্দ হিসেবে উঠে এসেছে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: dev.to ML
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...