Groq আউটেজে বিপর্যয়, ডেভেলপাররা AI রাউটিং বদলে দিলেন
একজন ডেভেলপার Groq-এর আউটেজের পর LLM ক্যাটেগোরাইজার বাদ দিয়ে এম্বেডিং-ভিত্তিক রাউটিং চালু করেছেন। সিস্টেম নীরবে মিডিয়াম টিয়ারে চলে গিয়েছিল, যা ব্যবহারকারীর অভিজ্ঞতায় প্রভাব ফেলেছে। এই পরিবর্তন কীভাবে AI সিস্টেমকে আরও সাশ্রয়ী ও নির্ভরযোগ্য করে তুলতে পারে, তা জানুন।
একজন ডেভেলপার Groq-এর আউটেজের পর LLM ক্যাটেগোরাইজার বাদ দিয়ে এম্বেডিং-ভিত্তিক রাউটিং চালু করেছেন। সিস্টেম নীরবে মিডিয়াম টিয়ারে চলে গিয়েছিল, যা ব্যবহারকারীর অভিজ্ঞতায় প্রভাব ফেলেছে। এই পরিবর্তন কীভাবে AI সিস্টেমকে আরও সাশ্রয়ী ও নির্ভরযোগ্য করে তুলতে পারে, তা জানুন।
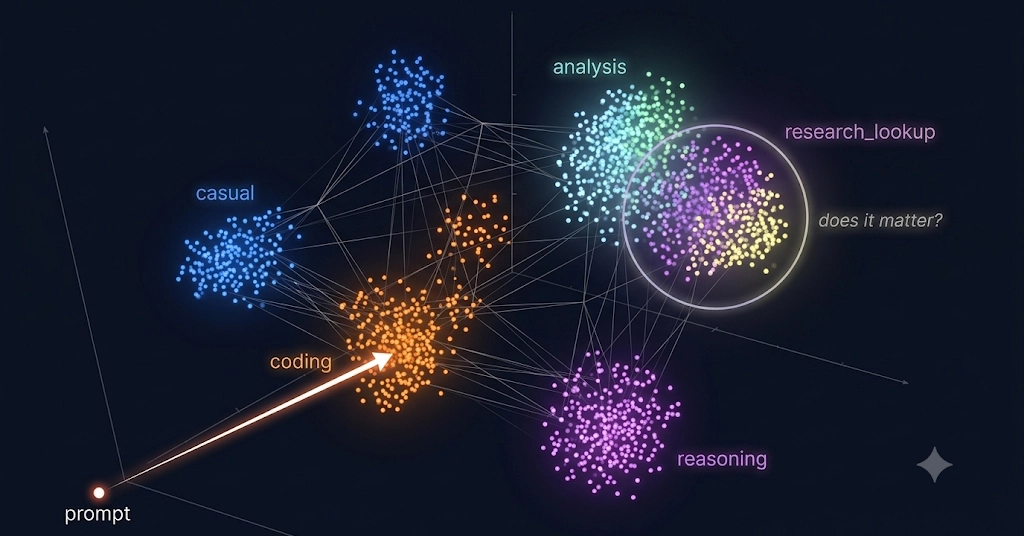
একজন সফটওয়্যার ডেভেলপার তার AI সিস্টেমের রাউটিং পদ্ধতি পুরোপুরি বদলে দিয়েছেন। তিনি LLM ক্যাটেগোরাইজার বাদ দিয়ে স্থানীয় multilingual-e5-large এম্বেডিং মডেল ব্যবহার শুরু করেছেন। এই পরিবর্তনের পেছনে মূল কারণ ছিল Groq-এর একটি বড় আউটেজ।
ঘটনাটি ঘটে 2026 সালের 22 মে। Groq তখন প্রায় দুই ঘণ্টা ডাউন ছিল। ওই সময়ে সিস্টেমটি নীরবে মিডিয়াম টিয়ারে চলে যায়। ব্যবহারকারীদের কাছে কোনো ত্রুটি বার্তা আসেনি। কিন্তু তারা যে মডেল পাওয়ার কথা ছিল, তা পাননি।
ডেভেলপার নিজেই বলেছেন, এই ঘটনাই তাকে এম্বেডিং-ভিত্তিক ফলব্যাক সিস্টেম চালু করতে বাধ্য করেছে। তার আগের পোস্টে তিনি LLM ক্যাটেগোরাইজার ব্যবহারের পরিকল্পনার কথা জানিয়েছিলেন। কিন্তু Groq-এর আউটেজ প্রমাণ করে দেয় যে শুধু একটি API-র ওপর নির্ভর করা ঝুঁকিপূর্ণ।
নতুন পদ্ধতিতে সিস্টেমটি আগের বার্তাগুলোর সঙ্গে মিল খুঁজে বের করে। এটি multilingual-e5-large এম্বেডিং ব্যবহার করে অনুরূপ বার্তা খুঁজে পায়। তারপর সেগুলোর ক্যাটাগরির ওপর ভোট দিয়ে সিদ্ধান্ত নেয়। এতে কোনো API কলের প্রয়োজন হয় না।
এই পরিবর্তনটি শুধু নির্ভরযোগ্যতা বাড়ায়নি, বরং খরচও কমিয়েছে। LLM-এর মাধ্যমে ক্যাটাগরি নির্ধারণের চেয়ে এম্বেডিং-ভিত্তিক পদ্ধতি অনেক সস্তা। কারণ এতে প্রতি অনুরোধের জন্য বাইরের কোনো API-তে কল করতে হয় না।
বাংলাদেশের ডেভেলপার ও ফ্রিল্যান্সারদের জন্য এই খবর বিশেষভাবে গুরুত্বপূর্ণ। অনেক স্থানীয় ডেভেলপার Groq বা অন্যান্য AI API ব্যবহার করেন। একটি আউটেজ তাদের পুরো অ্যাপ্লিকেশনকে অকেজো করে দিতে পারে। এম্বেডিং-ভিত্তিক ফলব্যাক সিস্টেম সেই ঝুঁকি কমাতে পারে।
বাংলাদেশে AI-ভিত্তিক স্টার্টআপগুলোর জন্য এটি একটি সাশ্রয়ী সমাধান হতে পারে। তারা স্থানীয় মডেল ব্যবহার করে API খরচ বাঁচাতে পারে। একই সঙ্গে সিস্টেমের নির্ভরযোগ্যতাও বাড়ে।
ডেভেলপারটি ভবিষ্যতে আরও উন্নতির পরিকল্পনা করছেন। তিনি বিভিন্ন ভাষার জন্য আলাদা এম্বেডিং মডেল ব্যবহার করার কথা ভাবছেন। এতে করে সিস্টেমটি আরও নির্ভুলভাবে ক্যাটাগরি নির্ধারণ করতে পারবে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: dev.to AI
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...