গেমা মডেলের তথ্য পুনরুদ্ধার প্রক্রিয়া উন্মোচন, AI গবেষণায় বড় অগ্রগতি
Activation patching কৌশল ব্যবহার করে গবেষকরা দেখিয়েছেন কিভাবে Gemma-2B এবং Gemma-12B-IT মডেল তথ্য সংরক্ষণ, রাউটিং এবং পুনরুদ্ধার করে। রেসিডুয়াল স্ট্রিম এই প্রক্রিয়ায় সবচেয়ে গুরুত্বপূর্ণ ভূমিকা পালন করে।
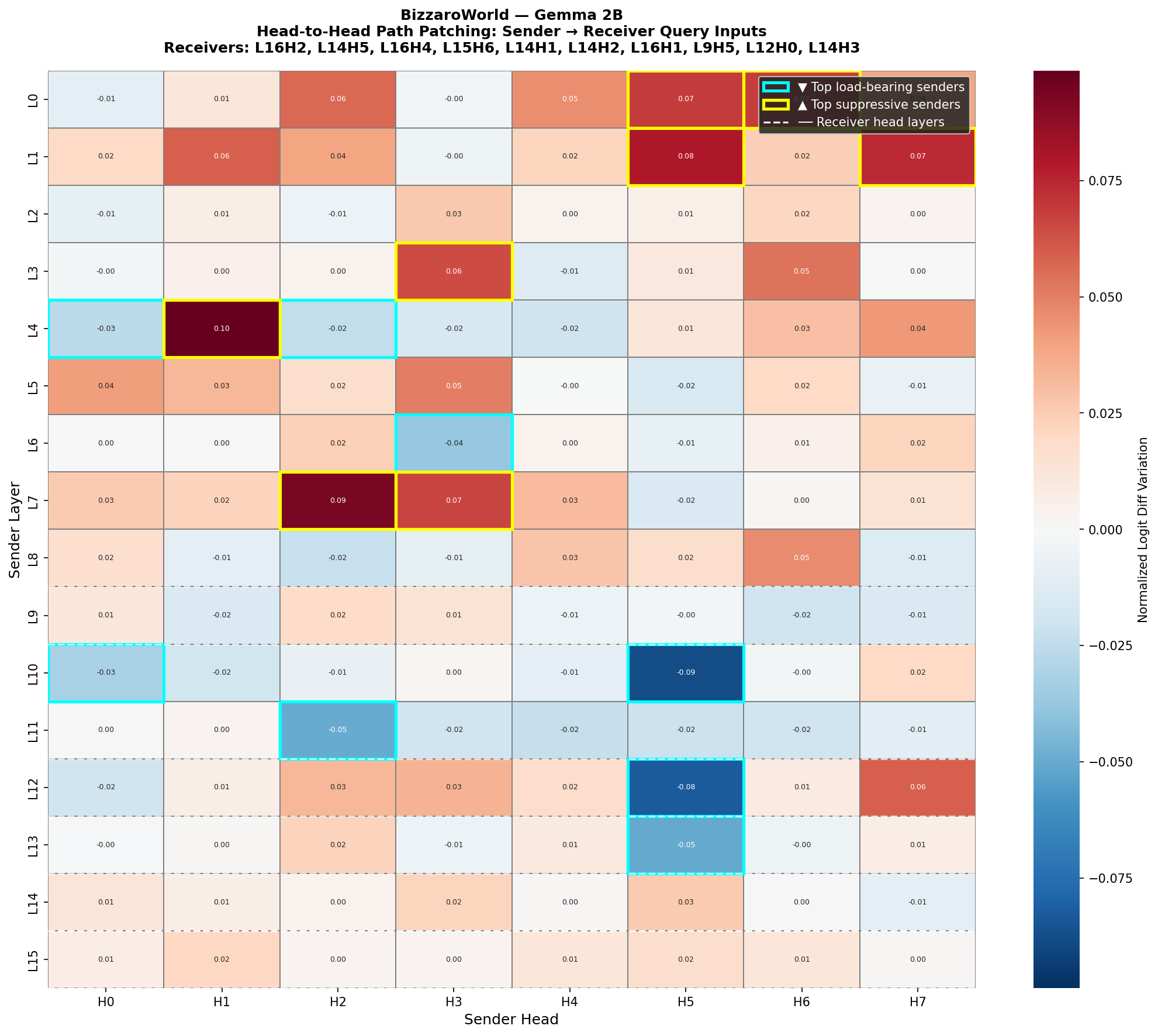
Activation patching কৌশল ব্যবহার করে গবেষকরা দেখিয়েছেন কিভাবে Gemma-2B এবং Gemma-12B-IT মডেল তথ্য সংরক্ষণ, রাউটিং এবং পুনরুদ্ধার করে। রেসিডুয়াল স্ট্রিম এই প্রক্রিয়ায় সবচেয়ে গুরুত্বপূর্ণ ভূমিকা পালন করে।
গুগলের জেমিনি পরিবারের ছোট মডেল Gemma-2B এবং Gemma-12B-IT-এর অভ্যন্তরীণ কাজ নিয়ে একটি গুরুত্বপূর্ণ গবেষণা প্রকাশিত হয়েছে। টুওয়ার্ডস ডাটা সায়েন্সে প্রকাশিত এই গবেষণায় দেখা গেছে, এই মডেলগুলো তথ্য পুনরুদ্ধারের জন্য একটি তিন-পর্যায়ের সার্কিট ব্যবহার করে।
গবেষকরা activation patching নামক একটি কৌশল ব্যবহার করেছেন। এই কৌশলের মাধ্যমে মডেলের নির্দিষ্ট অংশের কার্যকলাপ পরিবর্তন করে দেখা হয় যে সেই অংশটি মডেলের আউটপুটে কতটা প্রভাব ফেলে। এই পদ্ধতি ব্যবহার করে তারা ট্রান্সফরমার লেয়ার জুড়ে তথ্য কীভাবে সংরক্ষিত, রাউটেড এবং পুনরুদ্ধার হয় তা চিহ্নিত করেছেন।
এই গবেষণার মূল আবিষ্কার হলো রেসিডুয়াল স্ট্রিমের ভূমিকা। রেসিডুয়াল স্ট্রিম হলো মডেলের একটি কেন্দ্রীয় তথ্য পথ যা প্রতিটি ট্রান্সফরমার লেয়ারের সাথে সংযুক্ত। গবেষকরা দেখিয়েছেন যে তথ্য পুনরুদ্ধারের বেশিরভাগ কাজ এই রেসিডুয়াল স্ট্রিমের মাধ্যমেই সম্পন্ন হয়। এটি মডেলের বিভিন্ন অংশের মধ্যে তথ্য আদান-প্রদানের একটি দক্ষ মাধ্যম হিসেবে কাজ করে।
তিন-পর্যায়ের এই সার্কিটটি নিম্নরূপ কাজ করে: প্রথম পর্যায়ে তথ্য সংরক্ষিত হয় মডেলের নির্দিষ্ট নিউরনে। দ্বিতীয় পর্যায়ে এই তথ্য সঠিক আউটপুটের জন্য প্রয়োজনীয় স্থানে রাউট বা নির্দেশিত হয়। তৃতীয় পর্যায়ে এই তথ্য পুনরুদ্ধার করে আউটপুট জেনারেট করা হয়। প্রতিটি পর্যায়ই মডেলের বিভিন্ন ট্রান্সফরমার লেয়ারের মধ্যে সমন্বিতভাবে কাজ করে।
এই গবেষণার ফলাফল বাংলাদেশের AI গবেষক এবং ডেভেলপারদের জন্য বিশেষ গুরুত্বপূর্ণ। দেশে যারা ছোট এবং দক্ষ ভাষা মডেল তৈরি করতে চান, তাদের জন্য এই গবেষণা মডেলের অভ্যন্তরীণ কাজ বোঝার একটি নতুন দিক উন্মোচন করে। বিশেষ করে ফ্রিল্যান্সার এবং শিক্ষার্থীরা এই জ্ঞান ব্যবহার করে আরও কার্যকর মডেল তৈরি করতে পারবেন।
ভবিষ্যতে এই গবেষণা আরও বড় মডেলের জন্যও প্রযোজ্য হবে বলে আশা করা যায়। গবেষকরা এখন বুঝতে পেরেছেন কিভাবে তথ্য মডেলের মধ্যে সংরক্ষিত এবং পুনরুদ্ধার হয়। এই জ্ঞান ব্যবহার করে আরও নির্ভরযোগ্য এবং ব্যাখ্যাযোগ্য AI সিস্টেম তৈরি করা সম্ভব হবে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: Towards Data Science
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...