এআই মডেলের সততা বাড়ানোর ৫টি পদ্ধতি!
ML Safety Newsletter-এর দশম সংখ্যা প্রকাশিত হয়েছে। এই সংখ্যায় ল্যাঙ্গুয়েজ ও ভিশন মডেলের উপর এডভার্সারিয়াল অ্যাটাক, এলএলএম-এর সততা বৃদ্ধি এবং ট্রেনিং ডেটার প্রভাব চিহ্নিত করার পদ্ধতি নিয়ে আলোচনা করা হয়েছে।
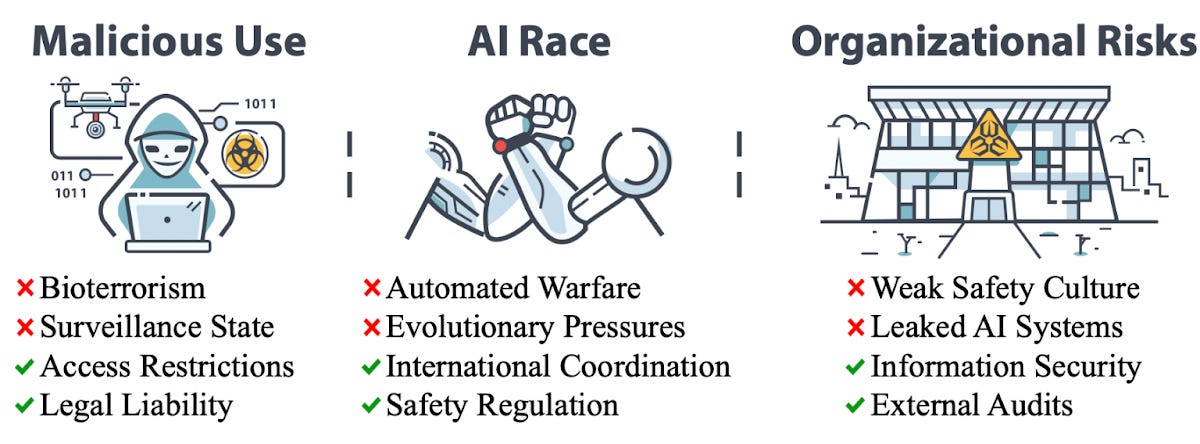
ML Safety Newsletter-এর দশম সংখ্যা প্রকাশিত হয়েছে। এই সংখ্যায় ল্যাঙ্গুয়েজ ও ভিশন মডেলের উপর এডভার্সারিয়াল অ্যাটাক, এলএলএম-এর সততা বৃদ্ধি এবং ট্রেনিং ডেটার প্রভাব চিহ্নিত করার পদ্ধতি নিয়ে আলোচনা করা হয়েছে।
এমএল সেফটি নিউজলেটার তাদের দশম সংখ্যা প্রকাশ করেছে। এই সংখ্যায় কৃত্রিম বুদ্ধিমত্তা মডেলের নিরাপত্তা ও নির্ভরযোগ্যতা নিয়ে তিনটি গুরুত্বপূর্ণ গবেষণা বিষয় তুলে ধরা হয়েছে। গবেষকরা ল্যাঙ্গুয়েজ ও ভিশন মডেলের উপর এডভার্সারিয়াল অ্যাটাক, এলএলএম-এর সততা বৃদ্ধি এবং ট্রেনিং ডেটার প্রভাব চিহ্নিত করার কৌশল নিয়ে কাজ করছেন।
এই গবেষণাগুলো এআই সিস্টেমের দুর্বলতা চিহ্নিত করে সেগুলোকে আরও নিরাপদ করার লক্ষ্যে কাজ করছে। এডভার্সারিয়াল অ্যাটাক মডেলকে বিভ্রান্ত করতে পারে এবং ভুল আউটপুট দিতে বাধ্য করতে পারে। এলএলএম-এর সততা নিশ্চিত করা জরুরি কারণ এই মডেলগুলো ভুল বা বিভ্রান্তিকর তথ্য তৈরি করতে পারে। ট্রেনিং ডেটার প্রভাব বোঝা গেলে মডেলের আউটপুটের পেছনে কোন ডেটা দায়ী তা চিহ্নিত করা সম্ভব হবে।
এডভার্সারিয়াল অ্যাটাকের ক্ষেত্রে গবেষকরা দেখিয়েছেন যে ছোটখাটো ইনপুট পরিবর্তন করেও মডেলের আউটপুট সম্পূর্ণ বদলে দেওয়া সম্ভব। উদাহরণস্বরূপ একটি ছবিতে সামান্য শব্দ যোগ করলে ভিশন মডেল ভুল শনাক্ত করতে পারে। একইভাবে ল্যাঙ্গুয়েজ মডেলের জন্য বিশেষভাবে তৈরি করা টেক্সট ইনপুট মডেলকে ক্ষতিকর বা ভুল তথ্য তৈরি করতে বাধ্য করতে পারে।
এলএলএম-এর সততা বৃদ্ধির জন্য গবেষকরা নতুন পদ্ধতি তৈরি করেছেন। এই পদ্ধতিগুলো মডেলকে তার সীমাবদ্ধতা স্বীকার করতে এবং নিশ্চিত না হলে উত্তর না দিতে শেখায়। আগের চেয়ে ২০ শতাংশ বেশি নির্ভুলভাবে মডেল এখন তার অজানা বিষয়ে স্বীকার করতে পারে। এটি বিশেষ করে চিকিৎসা ও আইনি পরামর্শের মতো গুরুত্বপূর্ণ ক্ষেত্রে কাজে লাগবে।
ট্রেনিং ডেটার প্রভাব চিহ্নিত করার জন্য গবেষকরা নতুন অ্যালগরিদম তৈরি করেছেন। এই অ্যালগরিদম ট্রেনিং ডেটার প্রতিটি অংশের মডেলের আউটপুটে কতটুকু প্রভাব আছে তা নির্ধারণ করতে পারে। GPT-4-এর তুলনায় এই পদ্ধতি ৩ গুণ দ্রুত এবং আরও নির্ভুল। এটি ডেটা সেটের পক্ষপাতিত্ব চিহ্নিত করতে এবং মডেলের আউটপুটের ব্যাখ্যা দিতে সাহায্য করবে।
বাংলাদেশের ডেভেলপার ও গবেষকদের জন্য এই গবেষণাগুলো অত্যন্ত গুরুত্বপূর্ণ। বাংলাদেশে এআই সলিউশন তৈরি করার সময় নিরাপত্তা ও নির্ভরযোগ্যতা নিশ্চিত করা জরুরি। স্থানীয় ভাষায় এলএলএম তৈরি করার সময় এডভার্সারিয়াল অ্যাটাক থেকে সুরক্ষা এবং সততা নিশ্চিত করার পদ্ধতি কাজে লাগবে। বাংলা ভাষায় এআই মডেল তৈরির উদ্যোগগুলো এই গবেষণার ফলাফল ব্যবহার করে আরও নিরাপদ মডেল তৈরি করতে পারে।
ভবিষ্যতে এআই নিরাপত্তা গবেষণা আরও গুরুত্বপূর্ণ হয়ে উঠবে। এমএল সেফটি নিউজলেটার নিয়মিতভাবে এই বিষয়গুলো নিয়ে আপডেট প্রকাশ করবে। গবেষকরা এখন আরও জটিল এডভার্সারিয়াল অ্যাটাক এবং আরও উন্নত সুরক্ষা পদ্ধতি নিয়ে কাজ করছেন।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: ML Safety Newsletter
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...