DeepSeek-V4-এ নতুন পদ্ধতি, GPU মেমরি সংকট কমিয়ে দেবে ৩ গুণ
গবেষকরা DeepSeek-V4 আর্কিটেকচারে Lookahead Sparse Attention (LSA) নামে একটি নতুন পদ্ধতি তৈরি করেছে। এটি কেবল গুরুত্বপূর্ণ KV ক্যাশ ধরে রেখে GPU মেমরির বোঝা কমিয়ে দেবে। ফলে অতি-দীর্ঘ কনটেক্সট ইনফারেন্স দ্রুত ও সাশ্রয়ী হবে।
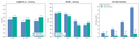
গবেষকরা DeepSeek-V4 আর্কিটেকচারে Lookahead Sparse Attention (LSA) নামে একটি নতুন পদ্ধতি তৈরি করেছে। এটি কেবল গুরুত্বপূর্ণ KV ক্যাশ ধরে রেখে GPU মেমরির বোঝা কমিয়ে দেবে। ফলে অতি-দীর্ঘ কনটেক্সট ইনফারেন্স দ্রুত ও সাশ্রয়ী হবে।
বিশ্বের সবচেয়ে বড় ভাষার মডেলগুলোকে চালানোর সময় সবচেয়ে বড় বাধা হলো GPU মেমরির সীমাবদ্ধতা। প্রচলিত পদ্ধতিতে ডিকোডিংয়ের সময় মডেলটি সব পুরনো টোকেনের KV ক্যাশ (Key-Value cache) মেমরিতে জমা রাখে। কিন্তু কনটেক্সট দীর্ঘ হলে এই ক্যাশের আকার এতটাই বেড়ে যায় যে এটি GPU মেমরির পুরো জায়গা দখল করে ফেলে। সম্প্রতি Reddit-এর r/LocalLLaMA ফোরামে প্রকাশিত একটি গবেষণাপত্রে এই সমস্যার একটি সম্ভাব্য সমাধান দেখানো হয়েছে।
গবেষকরা DeepSeek-V4 আর্কিটেকচারের ওপর ভিত্তি করে Lookahead Sparse Attention (LSA) নামের একটি অভিনব ইনফারেন্স প্যারাডাইম তৈরি করেছেন। LSA-র মূল বৈশিষ্ট্য হলো এটি ভবিষ্যতের কনটেক্সট চাহিদা আগে থেকেই অনুমান করে। এতে করে মডেলটি কেবলমাত্র সেই নির্দিষ্ট KV চাঙ্কগুলোই GPU মেমরিতে রাখে যা আসন্ন প্রশ্নের উত্তর দেওয়ার জন্য সত্যিই প্রয়োজনীয়। বাকি সব অপ্রয়োজনীয় ক্যাশ ডাটা তাৎক্ষণিকভাবে মুছে ফেলা হয়।
এই প্রক্রিয়াটি কাজ করে Neural Memory Indexer নামের একটি বিশেষ উপাদানের মাধ্যমে। এই ইনডেক্সারটি মডেলের আর্কিটেকচারের ভেতরেই তৈরি করা হয়েছে। এটি প্রতিটি নতুন টোকেন আসার আগে ভবিষ্যদ্বাণী করে যে কোন পুরনো টোকেনগুলোর তথ্য ভবিষ্যতে কাজে লাগবে। এরপর এটি শুধুমাত্র সেইসব ক্রিটিক্যাল KV চাঙ্কগুলোকে ক্যাশে করে রাখে। ফলে মেমরি ব্যবহারের পরিমাণ নাটকীয়ভাবে কমে যায়।
এই গবেষণার সবচেয়ে বড় সাফল্য হলো এটি অতি-দীর্ঘ কনটেক্সট (যেমন ১ মিলিয়ন টোকেন বা তার বেশি) ইনফারেন্সকে কার্যকরী করে তুলতে পারে। আগের মডেলগুলোতে এত দীর্ঘ কনটেক্সট চালাতে গেলে GPU মেমরি ফুরিয়ে যেত বা ইনফারেন্সের গতি অনেক কমে যেত। LSA সেই সীমাবদ্ধতা দূর করে দ্রুত এবং সাশ্রয়ী ইনফারেন্সের পথ খুলে দিয়েছে।
বাংলাদেশের ডেভেলপার ও ফ্রিল্যান্সারদের জন্য এই গবেষণার তাৎপর্য অনেক। বর্তমানে স্থানীয় কম্পিউটারে বড় ভাষার মডেল চালাতে গেলে মেমরির অভাবে প্রায়ই সমস্যা হয়। LSA পদ্ধতি ব্যবহার করে কম GPU মেমরি থাকা সিস্টেমেও অতি-দীর্ঘ ডকুমেন্ট বা কোডবেস নিয়ে কাজ করা সম্ভব হবে। বিশেষ করে যারা AI-ভিত্তিক অ্যাপ্লিকেশন, চ্যাটবট বা ডেটা অ্যানালাইসিস টুল তৈরি করছেন, তাদের জন্য এটি বড় সুবিধা বয়ে আনবে।
ভবিষ্যতে এই পদ্ধতি বাণিজ্যিক মডেলগুলোতে অন্তর্ভুক্ত হলে AI পরিষেবার খরচ কমবে। কারণ ক্লাউডে মডেল চালানোর সময় GPU মেমরি ভাড়া নেওয়ার খরচ অনেকটাই কমে যাবে। গবেষকরা ইতিমধ্যে DeepSeek-V4-তে LSA-র কার্যকারিতা প্রমাণ করেছেন। আশা করা যায়, শীঘ্রই এটি ওপেন সোর্স কমিউনিটিতেও পাওয়া যাবে।
এখন দেখার বিষয়, এই লুকাহেড স্পার্স অ্যাটেনশন পদ্ধতি বাস্তব বিশ্বের জটিল কাজে কতটা কার্যকর প্রমাণিত হয়। তবে প্রাথমিক ফলাফল বলছে, এটি GPU মেমরি সংকটের এক স্থায়ী সমাধান হতে পারে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: Reddit r/LocalLLaMA
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...