ChatGPT-র টোকেন স্ট্রিমিং: পর্দার আড়ালে vLLM ও TensorRT-LLM-এর কৌশল
আপনি যখন ChatGPT-তে টোকেন স্ট্রিম হতে দেখেন, পর্দার আড়ালে চলে জটিল এক অপারেশন। vLLM, TensorRT-LLM-এর মতো ফ্রেমওয়ার্ক কীভাবে সেই টোকেন তৈরি, শিডিউলিং ও মেমোরি ব্যবস্থাপনা করে? dev.to ML-এর একটি নিবন্ধ সেই পাইপলাইন খুলে বলছে।
আপনি যখন ChatGPT-তে টোকেন স্ট্রিম হতে দেখেন, পর্দার আড়ালে চলে জটিল এক অপারেশন। vLLM, TensorRT-LLM-এর মতো ফ্রেমওয়ার্ক কীভাবে সেই টোকেন তৈরি, শিডিউলিং ও মেমোরি ব্যবস্থাপনা করে? dev.to ML-এর একটি নিবন্ধ সেই পাইপলাইন খুলে বলছে।
আপনি যখন ChatGPT বা যেকোনো AI চ্যাটবটে একটি প্রশ্ন টাইপ করেন, তখন উত্তরটি টুকরো টুকরো করে আপনার স্ক্রিনে ভেসে আসে। এই টুকরোগুলোকে বলা হয় টোকেন। কিন্তু এই টোকেন তৈরি হওয়ার পেছনে যে প্রযুক্তিগত জাদু কাজ করে, তা সাধারণ ব্যবহারকারীর চোখে পড়ে না। সম্প্রতি dev.to ML-এ প্রকাশিত একটি নিবন্ধে LLM ডিপ্লয়মেন্ট ফ্রেমওয়ার্ক vLLM, TensorRT-LLM এবং Hugging Face TGI-এর অন্তর্নিহিত অপারেশন পদ্ধতি বিস্তারিতভাবে ব্যাখ্যা করা হয়েছে।
এই নিবন্ধটি মূলত দেখায় কিভাবে উচ্চ-কনকারেন্সি পরিবেশে অর্থাৎ একই সময়ে হাজার হাজার ব্যবহারকারীর অনুরোধ সামলানোর সময় এই ফ্রেমওয়ার্কগুলো একটি নাজুক ভারসাম্য রক্ষা করে। তারা প্রম্পট প্রি-কম্পিউটেশন শিডিউল করে, মেমোরি সেগমেন্ট পেজিং করে, স্পেকুলেটিভ ডিকোডিং চেইন যাচাই করে এবং সিস্টেম-স্টলিং বটলনেক ক্র্যাশ এড়িয়ে চলে।
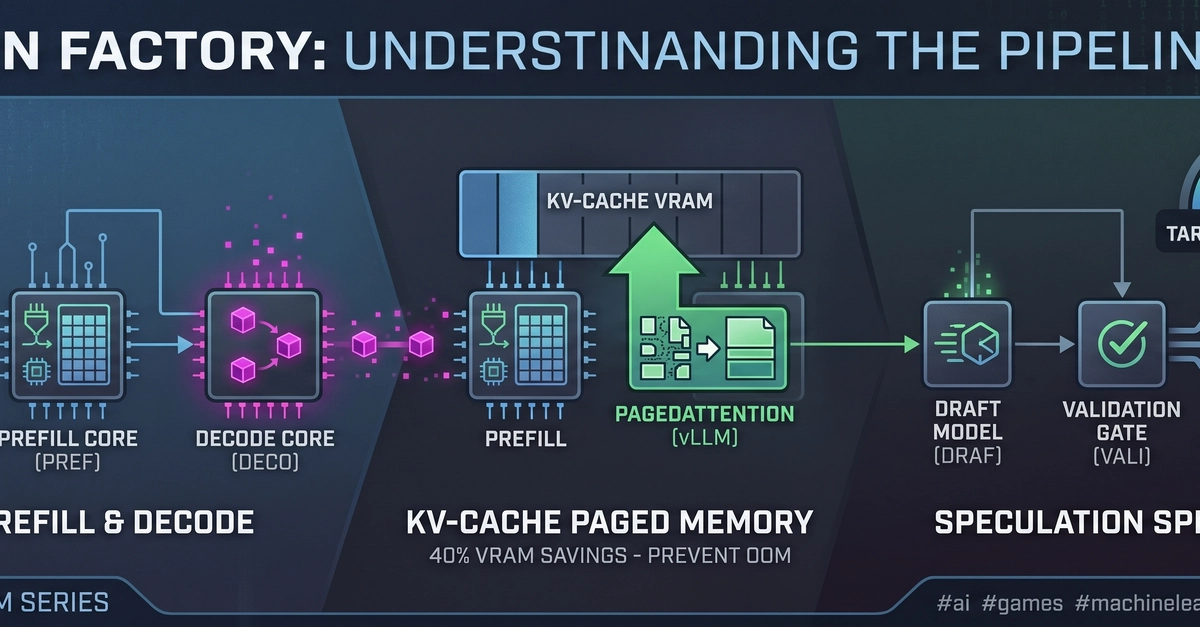
প্রথম গুরুত্বপূর্ণ বিষয় হলো শিডিউলিং। যখন একটি বড় মডেল, যেমন GPT-4 বা LLaMA, একই সময়ে অনেকগুলো অনুরোধ পায়, তখন সবগুলোকে একসঙ্গে প্রসেস করা সম্ভব নয়। vLLM এবং TensorRT-LLM একটি কৌশলী শিডিউলার ব্যবহার করে যা প্রম্পটের প্রি-কম্পিউটেশন এবং নতুন টোকেন জেনারেশনকে আলাদাভাবে পরিচালনা করে। এটি নিশ্চিত করে যে কোনো ব্যবহারকারীকে অন্যদের চেয়ে বেশি অপেক্ষা করতে না হয়।
দ্বিতীয়ত, মেমোরি পেজিং একটি অত্যন্ত গুরুত্বপূর্ণ কৌশল। বড় ভাষার মডেলগুলোর জন্য বিপুল পরিমাণ মেমোরি প্রয়োজন। GPU-তে মেমোরি সীমিত। তাই এই ফ্রেমওয়ার্কগুলো মেমোরিকে ছোট ছোট পৃষ্ঠায় ভাগ করে এবং প্রয়োজন অনুযায়ী সেগুলো লোড ও আনলোড করে। এটি মেমোরির অপচয় রোধ করে এবং দ্রুত টোকেন জেনারেশন নিশ্চিত করে।
তৃতীয় কৌশলটি হলো স্পেকুলেটিভ ডিকোডিং। এটি একটি ভবিষ্যদ্বাণীভিত্তিক পদ্ধতি। মডেল প্রথমে সম্ভাব্য কয়েকটি টোকেনের একটি চেইন অনুমান করে। তারপর সেই চেইনটি যাচাই করে। যদি অনুমান সঠিক হয়, তাহলে একসঙ্গে অনেকগুলো টোকেন আউটপুট করা যায়। এটি টোকেন জেনারেশনের গতি আগের চেয়ে ২ থেকে ৩ গুণ বাড়িয়ে দিতে পারে।
বাংলাদেশের জন্য এই প্রযুক্তির গুরুত্ব অপরিসীম। স্থানীয় স্টার্টআপ ও ডেভেলপাররা যদি নিজস্ব AI চ্যাটবট বা কাস্টমার সার্ভিস সিস্টেম তৈরি করতে চান, তাহলে তাদের এই ফ্রেমওয়ার্কগুলো বুঝতে হবে। বর্তমানে বাংলাদেশে AI-ভিত্তিক টুল তৈরির আগ্রহ বাড়ছে। কিন্তু উচ্চ-কনকারেন্সি সাপোর্ট না থাকলে সেই টুল ব্যবহারকারীর সংখ্যা বাড়ার সঙ্গে সঙ্গেই ধীর হয়ে যাবে বা ক্র্যাশ করবে। এই ফ্রেমওয়ার্কগুলো সেই সমস্যার সমাধান দেয়। ফ্রিল্যান্সার ডেভেলপারদের জন্যও এটি একটি গুরুত্বপূর্ণ দক্ষতা। আন্তর্জাতিক বাজারে LLM ডিপ্লয়মেন্ট বিশেষজ্ঞের চাহিদা দ্রুত বাড়ছে।
ভবিষ্যতে এই প্রযুক্তি আরও সহজলভ্য হবে বলে ধারণা করা হচ্ছে। vLLM এবং TensorRT-LLM-এর মতো ওপেন সোর্স টুলগুলো ইতিমধ্যেই ছোট দলের জন্যও বড় মডেল ডিপ্লয় করা সম্ভব করে তুলেছে। বাংলাদেশের ডেভেলপার ও শিক্ষার্থীদের এখনই এই টুলগুলো নিয়ে পরীক্ষা-নিরীক্ষা শুরু করা উচিত। কারণ আগামী দিনের AI অ্যাপ্লিকেশনগুলোর সাফল্য নির্ভর করবে তাদের অন্তর্নিহিত অবকাঠামোর ওপর।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: dev.to ML
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...