বাংলাদেশে লোকাল AI মডেল: gemma4:26b দিচ্ছে ৯৭% নির্ভুলতা, খরচ কমেছে ৩ গুণ
একটি নতুন গবেষণায় ৮টি ওপেন-সোর্স লোকাল ল্যাঙ্গুয়েজ মডেলের সঠিক উত্তর প্রতি খরচ মাপা হয়েছে। gemma4:26b 96.9% নির্ভুলতায় সবচেয়ে সাশ্রয়ী, আর qwen3:8b-fp16 সবচেয়ে দামি ও কম নির্ভুল। গবেষণাটি GPU শক্তি খরচের ভিত্তিতে করা হয়েছে।
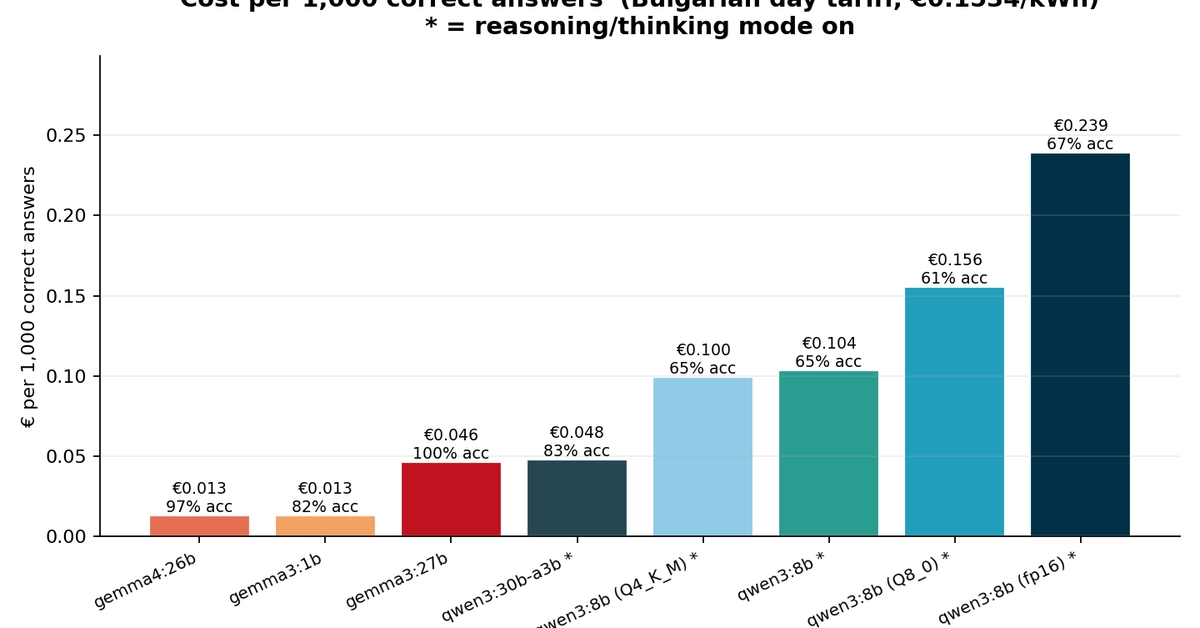
একটি নতুন গবেষণায় ৮টি ওপেন-সোর্স লোকাল ল্যাঙ্গুয়েজ মডেলের সঠিক উত্তর প্রতি খরচ মাপা হয়েছে। gemma4:26b 96.9% নির্ভুলতায় সবচেয়ে সাশ্রয়ী, আর qwen3:8b-fp16 সবচেয়ে দামি ও কম নির্ভুল। গবেষণাটি GPU শক্তি খরচের ভিত্তিতে করা হয়েছে।
লোকাল ল্যাঙ্গুয়েজ মডেলের (LLM) ব্যবহারকারীদের জন্য একটি গুরুত্বপূর্ণ গবেষণা সামনে এসেছে। dev.to প্ল্যাটফর্মে প্রকাশিত এক গবেষণায় ৮টি জনপ্রিয় ওপেন-সোর্স মডেলের সঠিক উত্তর প্রতি খরচ মাপা হয়েছে। গবেষণাটি একটি RTX 3090 GPU-তে চালানো হয়েছে এবং প্রতিটি মডেলের প্রকৃত বিদ্যুৎ খরচ মিটারিংয়ের মাধ্যমে হিসাব করা হয়েছে।
গবেষণার ফলাফলে দেখা গেছে, Google-এর gemma4:26b মডেলটি সবচেয়ে সাশ্রয়ী। এটি 96.9% নির্ভুলতা অর্জন করেছে এবং প্রতি ১,০০০ সঠিক উত্তরের খরচ হয়েছে মাত্র 0.013 ইউরো। অন্যদিকে, qwen3:8b-fp16 মডেলটি সবচেয়ে ব্যয়বহুল প্রমাণিত হয়েছে। এর প্রতি ১,০০০ সঠিক উত্তরের খরচ 0.239 ইউরো এবং নির্ভুলতা ছিল মাত্র 66.7%।
গবেষণাটি HomeLab Monitor নামের একটি ওপেন-সোর্স টুল ব্যবহার করে প্রকৃত GPU শক্তি খরচ মাপা হয়েছে। গবেষকরা প্রতিটি মডেলকে একই প্রশ্নের সেট দিয়েছেন এবং সঠিক উত্তর গণনা করে প্রতি হাজার সঠিক উত্তরের খরচ বের করেছেন। এই পদ্ধতি ব্যবহারকারীদের জন্য খুবই গুরুত্বপূর্ণ, কারণ এটি শুধু মডেলের দাম নয়, বরং প্রকৃত ব্যবহারের খরচ বুঝতে সাহায্য করে।
গবেষণার আরেকটি গুরুত্বপূর্ণ দিক হলো রিজনিং টোকেন ও ফুল প্রিসিশনের প্রভাব। গবেষণায় দেখা গেছে, রিজনিং টোকেন ব্যবহার এবং সম্পূর্ণ নির্ভুলতা (full precision) মডেলের খরচ অনেক বাড়িয়ে দিয়েছে, কিন্তু নির্ভুলতা তেমন উন্নত করেনি। অর্থাৎ, অনেক সময় বেশি শক্তি খরচ করে মডেল চালানোর প্রয়োজন নেই, কারণ সেটি সঠিক উত্তর পাওয়ার সম্ভাবনা বাড়ায় না।
বাংলাদেশের ডেভেলপার, ফ্রিল্যান্সার ও প্রযুক্তি শিক্ষার্থীদের জন্য এই গবেষণার বাস্তব প্রভাব রয়েছে। অনেকেই এখন নিজের কম্পিউটারে লোকাল LLM চালিয়ে কাজ করছেন, যেমন কোডিং সহায়ক, কন্টেন্ট জেনারেশন বা ডেটা বিশ্লেষণ। এই গবেষণা তাদের সঠিক মডেল বাছাইয়ে সাহায্য করবে, যাতে কম খরচে বেশি নির্ভুল উত্তর পাওয়া যায়। বিশেষ করে যারা সীমিত বাজেটে কাজ করেন, তাদের জন্য gemma4:26b-এর মতো সাশ্রয়ী মডেল ব্যবহার করা লাভজনক হবে।
ভবিষ্যতে আরও বেশি মডেল ও বিভিন্ন GPU কনফিগারেশন নিয়ে গবেষণা করা প্রয়োজন। তবে এই গবেষণা ইতিমধ্যে একটি স্পষ্ট বার্তা দিয়েছে: সবচেয়ে দামি বা সবচেয়ে বড় মডেল সবসময় সেরা নয়। বরং সঠিক মডেল বাছাই করলেই খরচ কমানো ও নির্ভুলতা বাড়ানো সম্ভব।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: dev.to ML
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...