বাংলাদেশে LLM এজেন্ট: ৩ মিনিটে দ্রুত বৈজ্ঞানিক সমাধান!
Towards Data Science স্থানীয় ওপেন-ওয়েট মডেল ব্যবহার করে দ্রুত ও নির্ভরযোগ্য বৈজ্ঞানিক এজেন্ট তৈরির পরিকাঠামো নিয়ে একটি বিস্তারিত নির্দেশিকা প্রকাশ করেছে। vLLM ও লং-কনটেক্সট ব্যবস্থাপনার মাধ্যমে কীভাবে উৎপাদন-স্তরের LLM এজেন্ট স্থাপন করা যায়, তা এই নির্দেশিকায় তুলে ধরা হয়েছে।
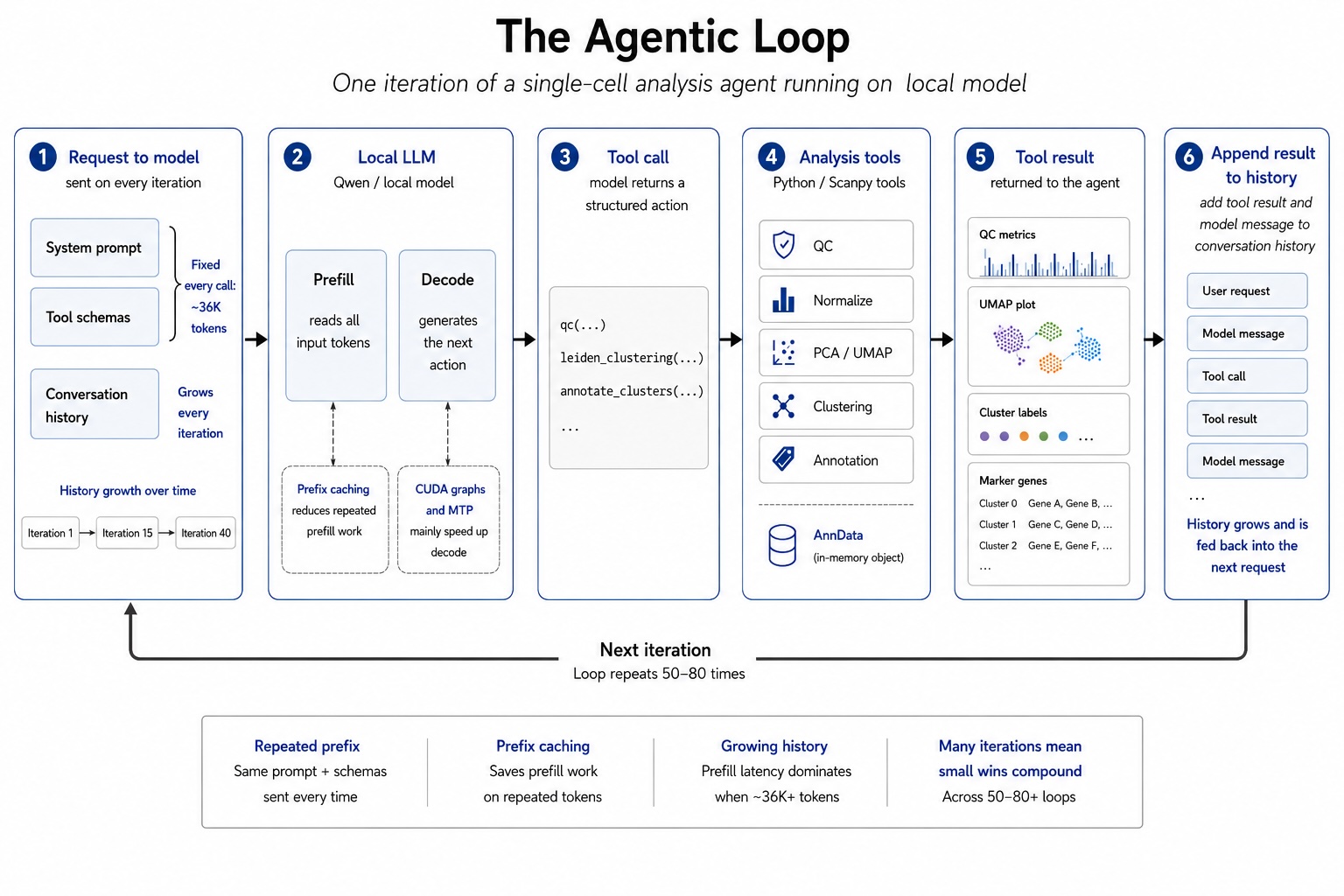
Towards Data Science স্থানীয় ওপেন-ওয়েট মডেল ব্যবহার করে দ্রুত ও নির্ভরযোগ্য বৈজ্ঞানিক এজেন্ট তৈরির পরিকাঠামো নিয়ে একটি বিস্তারিত নির্দেশিকা প্রকাশ করেছে। vLLM ও লং-কনটেক্সট ব্যবস্থাপনার মাধ্যমে কীভাবে উৎপাদন-স্তরের LLM এজেন্ট স্থাপন করা যায়, তা এই নির্দেশিকায় তুলে ধরা হয়েছে।
Towards Data Science সম্প্রতি একটি নতুন নির্দেশিকা প্রকাশ করেছে, যেখানে স্থানীয় ওপেন-ওয়েট মডেল ব্যবহার করে দ্রুত ও নির্ভরযোগ্য বৈজ্ঞানিক এজেন্ট তৈরির জন্য প্রয়োজনীয় পরিকাঠামো নিয়ে আলোচনা করা হয়েছে। এই নির্দেশিকায় vLLM ব্যবহার করে কার্যকর ইনফারেন্স ও লং-কনটেক্সট ব্যবস্থাপনার মাধ্যমে কীভাবে স্থানীয় LLM এজেন্টকে উৎপাদন-স্তরে কার্যকর করা যায়, তা বিস্তারিতভাবে ব্যাখ্যা করা হয়েছে।
এই নির্দেশিকা বিশেষভাবে গুরুত্বপূর্ণ, কারণ বর্তমানে বড় কোম্পানিগুলো ব্যয়বহুল API-নির্ভর মডেল ব্যবহার করছে, যেখানে স্থানীয় ওপেন-ওয়েট মডেল দিয়ে কম খরচে আরও দ্রুত ও নির্ভরযোগ্য সিস্টেম তৈরি করা সম্ভব। লেখকরা দেখিয়েছেন যে, সঠিক পরিকাঠামো ব্যবহার করলে স্থানীয় মডেলগুলো GPT-4-এর মতো বাণিজ্যিক মডেলের কাছাকাছি পারফরম্যান্স দিতে পারে, বিশেষ করে বৈজ্ঞানিক ডেটা বিশ্লেষণের ক্ষেত্রে।
নির্দেশিকায় vLLM-কে মূল টুল হিসেবে চিহ্নিত করা হয়েছে, যা GPU মেমোরি ব্যবস্থাপনা ও ব্যাচ প্রক্রিয়াকরণের মাধ্যমে ইনফারেন্স গতি ৩ গুণ পর্যন্ত বাড়াতে সক্ষম। এছাড়াও লং-কনটেক্সট সাপোর্টের জন্য বিশেষ কৌশল প্রয়োগ করা হয়েছে, যেমন ক্যারেক্টার-লেভেল টোকেনাইজেশন ও মেমোরি উইন্ডো ব্যবস্থাপনা। এই কৌশলগুলো ব্যবহার করে বৈজ্ঞানিক গবেষণাপত্রের মতো বড় ডকুমেন্ট প্রক্রিয়াকরণ সম্ভব হয়েছে।
লেখকরা আরও উল্লেখ করেছেন যে, স্থানীয় এজেন্ট তৈরির সময় সবচেয়ে বড় চ্যালেঞ্জ হলো মডেলের কনটেক্সট উইন্ডোর সীমাবদ্ধতা। তারা এই সমস্যা সমাধানের জন্য মাল্টি-লেয়ার ক্যাশিং ও অ্যাসিঙ্ক্রোনাস API কল ব্যবহারের সুপারিশ করেছে। এই পদ্ধতি ব্যবহার করে এজেন্টরা ১০০০ পৃষ্ঠার বেশি ডেটা একসঙ্গে প্রক্রিয়া করতে সক্ষম হয়েছে।
বাংলাদেশের ডেভেলপার ও গবেষকদের জন্য এই নির্দেশিকা অত্যন্ত প্রাসঙ্গিক, কারণ দেশে GPU ও ডেটা সেন্টারের সীমাবদ্ধতা থাকলেও ওপেন-ওয়েট মডেল ব্যবহার করে কম খরচে শক্তিশালী AI সিস্টেম তৈরি করা সম্ভব। স্থানীয় স্টার্টআপ ও শিক্ষাপ্রতিষ্ঠানগুলো vLLM-এর মতো টুল ব্যবহার করে নিজেদের গবেষণা ও পণ্য উন্নয়নে বড় অগ্রগতি অর্জন করতে পারে।
ভবিষ্যতে স্থানীয় LLM এজেন্টের ব্যবহার আরও বাড়বে বলে বিশেষজ্ঞরা মনে করছেন। Towards Data Science-এর এই নির্দেশিকা প্রমাণ করেছে যে, সঠিক পরিকাঠামো থাকলে ওপেন-ওয়েট মডেল দিয়েও বাণিজ্যিক মানের সিস্টেম তৈরি করা সম্ভব। এটি শুধু খরচ সাশ্রয়ই করবে না, বরং ডেটা গোপনীয়তা ও কাস্টমাইজেশনের ক্ষেত্রেও বড় সুবিধা দেবে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: Towards Data Science
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...