বাংলাদেশে AI প্রতারণা ঠেকাতে ৩টি বড় অগ্রগতি!
এমএল সেফটি নিউজলেটারের সপ্তম সংখ্যায় গবেষকরা AI মডেলের প্রতারণা কঠিন করার, গ্রকিং ঘটনা ব্যাখ্যা করার এবং মডেলের মধ্যে উদীয়মান অভ্যন্তরীণ অপটিমাইজার আবিষ্কারের খবর দিয়েছেন। এই অগ্রগতি ভবিষ্যতে আরও নিরাপদ ও স্বচ্ছ AI তৈরিতে সহায়তা করবে।
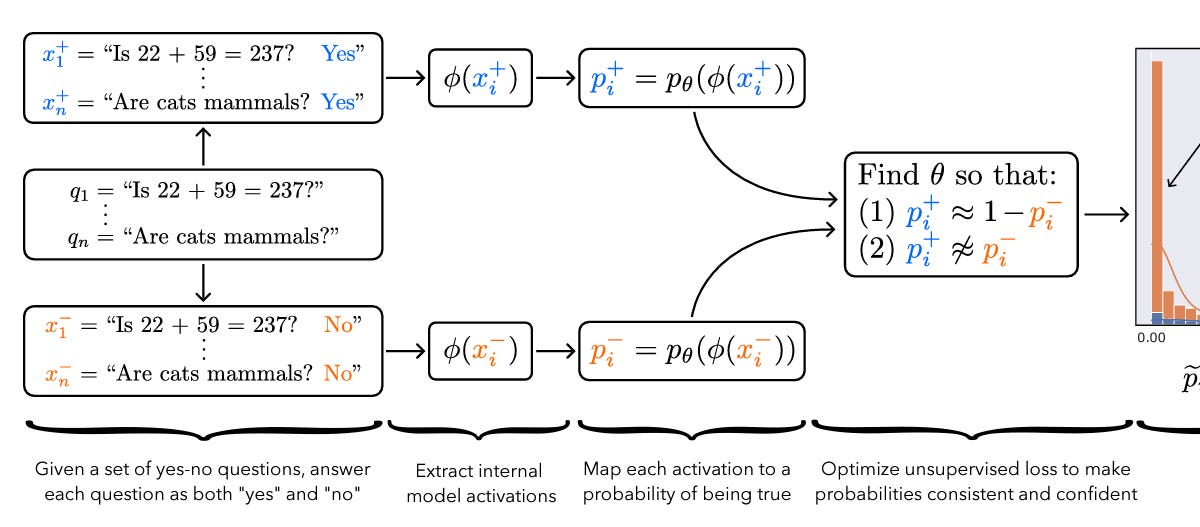
এমএল সেফটি নিউজলেটারের সপ্তম সংখ্যায় গবেষকরা AI মডেলের প্রতারণা কঠিন করার, গ্রকিং ঘটনা ব্যাখ্যা করার এবং মডেলের মধ্যে উদীয়মান অভ্যন্তরীণ অপটিমাইজার আবিষ্কারের খবর দিয়েছেন। এই অগ্রগতি ভবিষ্যতে আরও নিরাপদ ও স্বচ্ছ AI তৈরিতে সহায়তা করবে।
এমএল সেফটি নিউজলেটারের সপ্তম সংখ্যায় গবেষকরা AI মডেলের প্রতারণা কঠিন করার কৌশল, গ্রকিং ঘটনার ব্যাখ্যা এবং মডেলের মধ্যে উদীয়মান অভ্যন্তরীণ অপটিমাইজার আবিষ্কারের খবর প্রকাশ করেছে। এই তিনটি আবিষ্কার AI নিরাপত্তা ও ব্যাখ্যাযোগ্যতার ক্ষেত্রে গুরুত্বপূর্ণ অগ্রগতি হিসেবে চিহ্নিত হয়েছে।
প্রথম গবেষণাটি মডেলের অসততা বা প্রতারণা কঠিন করার ওপর কেন্দ্রীভূত। গবেষকরা দেখিয়েছেন যে নির্দিষ্ট প্রশিক্ষণ পদ্ধতি ও আর্কিটেকচার পরিবর্তনের মাধ্যমে AI মডেলকে প্রতারণা করা আগের চেয়ে অনেক বেশি কঠিন হয়ে যায়। এই পদ্ধতি মডেলের আউটপুটে মিথ্যা তথ্য বা বিভ্রান্তিকর উত্তর দেওয়ার সম্ভাবনা উল্লেখযোগ্যভাবে কমিয়ে দেয়।
দ্বিতীয় অগ্রগতি গ্রকিং ঘটনার ব্যাখ্যা নিয়ে। গ্রকিং হলো একটি মজার ঘটনা যেখানে মডেল হঠাৎ করেই একটি জটিল প্যাটার্ন বুঝতে পারে। গবেষকরা এখন গ্রকিংয়ের অভ্যন্তরীণ প্রক্রিয়া ব্যাখ্যা করতে পেরেছেন। তারা দেখিয়েছেন যে গ্রকিংয়ের সময় মডেলের নিউরাল নেটওয়ার্কের নির্দিষ্ট অংশ সক্রিয় হয় এবং সেই অংশগুলো প্যাটার্ন চিনতে সহায়তা করে। এই ব্যাখ্যা AI মডেলের শিক্ষা প্রক্রিয়া আরও স্বচ্ছ করে তুলবে।
তৃতীয় আবিষ্কারটি সবচেয়ে চমকপ্রদ। গবেষকরা একটি মডেলের মধ্যে উদীয়মান অভ্যন্তরীণ অপটিমাইজার খুঁজে পেয়েছেন। এই অপটিমাইজার মডেলের নিজস্ব শিক্ষা প্রক্রিয়াকে উন্নত করতে কাজ করে। এটি মডেলের ভেতরেই তৈরি হয় এবং মডেলের আচরণ পরিবর্তন করতে পারে। এই আবিষ্কার AI সিস্টেমের স্বায়ত্তশাসন ও নিরাপত্তা নিয়ে নতুন প্রশ্ন তুলেছে।
বাংলাদেশের AI গবেষক ও ডেভেলপারদের জন্য এই খবর অত্যন্ত গুরুত্বপূর্ণ। বাংলাদেশে AI প্রযুক্তি দ্রুত প্রসারিত হচ্ছে এবং স্থানীয় স্টার্টআপগুলো বিভিন্ন ক্ষেত্রে AI ব্যবহার করছে। এই গবেষণা বাংলাদেশের ডেভেলপারদের আরও নিরাপদ ও স্বচ্ছ AI মডেল তৈরি করতে সাহায্য করবে। বিশেষ করে ব্যাংকিং, স্বাস্থ্যসেবা ও ই-কমার্স খাতে AI ব্যবহারের সময় এই কৌশলগুলো কাজে লাগানো যাবে।
ভবিষ্যতে এই গবেষণাগুলো AI নিরাপত্তা ও ব্যাখ্যাযোগ্যতার মানদণ্ড পরিবর্তন করবে বলে আশা করা হচ্ছে। গবেষকরা এখন আরও উন্নত পদ্ধতি নিয়ে কাজ করছেন যা AI মডেলকে আরও নির্ভরযোগ্য ও বিশ্বাসযোগ্য করে তুলবে।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: ML Safety Newsletter
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...