AI-এর সিদ্ধান্ত এখন স্বচ্ছ: বাংলাদেশি ফ্রিল্যান্সারদের জন্য বড় সুবিধা
বড় ভাষার মডেলের সিদ্ধান্ত গ্রহণ প্রক্রিয়া বোঝা কঠিন। BAIR-এর নতুন গবেষণা ফিচার অ্যাট্রিবিউশনের মাধ্যমে এই জটিলতা কাটাতে চায়। গবেষণাটি নিরাপদ AI তৈরির পথে গুরুত্বপূর্ণ ভূমিকা রাখবে।
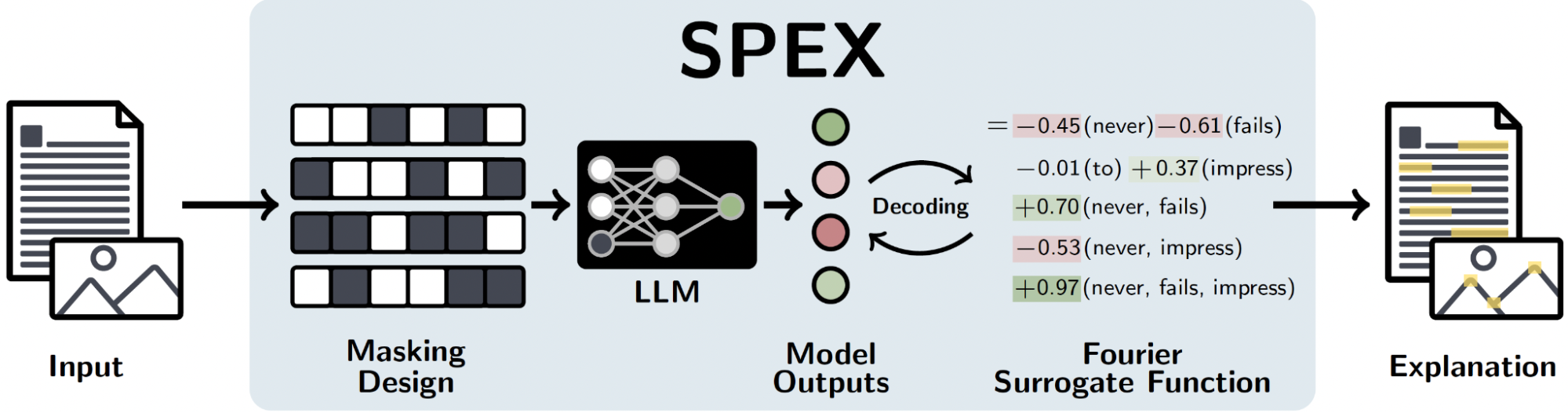
বড় ভাষার মডেলের সিদ্ধান্ত গ্রহণ প্রক্রিয়া বোঝা কঠিন। BAIR-এর নতুন গবেষণা ফিচার অ্যাট্রিবিউশনের মাধ্যমে এই জটিলতা কাটাতে চায়। গবেষণাটি নিরাপদ AI তৈরির পথে গুরুত্বপূর্ণ ভূমিকা রাখবে।
কৃত্রিম বুদ্ধিমত্তার জগতে বড় ভাষার মডেল বা LLM-এর ব্যবহার দিন দিন বাড়ছে। কিন্তু এই মডেলগুলো কীভাবে সিদ্ধান্ত নেয়, তা বোঝা এখনও একটি বড় চ্যালেঞ্জ। সম্প্রতি ক্যালিফোর্নিয়া বিশ্ববিদ্যালয় বার্কলির BAIR ল্যাব এই জটিলতা দূর করতে একটি গুরুত্বপূর্ণ গবেষণা প্রকাশ করেছে।
গবেষণাটির শিরোনাম ‘Identifying Interactions at Scale for LLMs’। এখানে গবেষকরা দেখিয়েছেন কীভাবে LLM-এর সিদ্ধান্ত গ্রহণ প্রক্রিয়াকে আরও স্বচ্ছ করা যায়। ইন্টারপ্রিটেবিলিটি গবেষণার লক্ষ্যই হলো মডেলের ভেতরে কী ঘটছে তা বোঝা। এই বোধগম্যতা নিরাপদ ও বিশ্বাসযোগ্য AI তৈরির জন্য অপরিহার্য।
গবেষণায় ফিচার অ্যাট্রিবিউশন নামক একটি পদ্ধতি ব্যবহার করা হয়েছে। এই পদ্ধতি মডেলের দেওয়া আউটপুটের জন্য দায়ী নির্দিষ্ট ইনপুট বৈশিষ্ট্যগুলোকে চিহ্নিত করে। সহজ ভাষায় বললে, এটি খুঁজে বের করে মডেলটি তার উত্তর দেওয়ার সময় কোন শব্দ বা তথ্যের ওপর বেশি নির্ভর করেছে। এই বিশ্লেষণ মডেলের পক্ষপাত বা ভুল বোঝার সম্ভাবনা কমাতে সাহায্য করে।
BAIR-এর এই গবেষণা আগের চেয়ে অনেক বড় স্কেলে কাজ করতে পারে। সাধারণত ছোট মডেলের ওপর এই ধরনের বিশ্লেষণ করা হতো। কিন্তু নতুন পদ্ধতি GPT-4-এর মতো বড় মডেলের জন্যও কার্যকর। গবেষকরা বলছেন, এই পদ্ধতি ব্যবহার করে মডেলের ভেতরের জটিল আন্তঃসম্পর্ক বোঝা সম্ভব হবে।
বাংলাদেশের জন্য এই গবেষণার গুরুত্ব অনেক। দেশের স্টার্টআপ ও প্রযুক্তি কোম্পানিগুলো দিন দিন AI নির্ভর সেবা তৈরি করছে। ফ্রিল্যান্সার ও ডেভেলপাররা ChatGPT বা অন্যান্য API ব্যবহার করে অ্যাপ্লিকেশন বানাচ্ছে। এই গবেষণা তাদের বুঝতে সাহায্য করবে কেন একটি মডেল নির্দিষ্ট উত্তর দিচ্ছে। এর ফলে তারা আরও নির্ভরযোগ্য ও নিরাপদ সেবা তৈরি করতে পারবে।
শিক্ষার্থীদের জন্যও এটি একটি দারুণ সুযোগ। ঢাকা বিশ্ববিদ্যালয় ও বুয়েটের মতো প্রতিষ্ঠানে AI গবেষণা বাড়ছে। এই ধরনের গবেষণা তাদের জটিল মডেল বোঝার পথ খুলে দেবে। বাংলাদেশের গবেষকরাও এই পদ্ধতি ব্যবহার করে নিজস্ব মডেলের স্বচ্ছতা বাড়াতে পারবেন।
ভবিষ্যতে এই গবেষণা আরও বড় প্রভাব ফেলতে পারে। নিরাপদ AI তৈরির জন্য স্বচ্ছতা একটি মৌলিক শর্ত। BAIR-এর এই কাজ সেই পথেই একটি বড় পদক্ষেপ। গবেষকরা আশা করছেন, এই পদ্ধতি ব্যবহার করে আমরা শীঘ্রই আরও বোধগম্য ও বিশ্বাসযোগ্য AI সিস্টেম দেখতে পাব।
আরও পড়ুন
এই সংবাদটি আন্তর্জাতিক সূত্রের তথ্য অবলম্বনে AI-সহায়তায় বাংলায় উপস্থাপন ও বাংলাদেশের প্রেক্ষাপটে সম্পাদিত। মূল তথ্যের জন্য নিচের সূত্র দেখুন।
মূল প্রতিবেদন: BAIR Berkeley
সোর্স দেখুন ↗মন্তব্য০
লোড হচ্ছে...